AiMOS Environment Basics
Initial Environment Setup
The following sections are the steps for setting up your environment.
Set up passwordless
It is strongly recommended that you set up the passwordless to login to the front end nodes and compute nodes. This is particularly required if you are running MPI workload. You only need to do this once. The process consists of two steps:
Generate the key using ssh-keygen command.
Concatenate the generated key to the authorized_keys file.
The following example assumes you already log in to either one of the landing pad nodes or one of the front end nodes.
$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/gpfs/u/home/BMHR/BMHRkmkh/.ssh/id_rsa):
/gpfs/u/home/BMHR/BMHRkmkh/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /gpfs/u/home/BMHR/BMHRkmkh/.ssh/id_rsa.
Your public key has been saved in /gpfs/u/home/BMHR/BMHRkmkh/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:I7OYesm4IUs9vHbtXoYi4vy7dAOt9FMPJoQ8ssiibcI
BMHRkmkh@dcsfen01
The key's randomart image is:
+---[RSA 2048]----+
| |
| . . |
| . + . |
|o o + |
|oo o oo+S |
|+.+ +o+++. |
|+E+XoBo. + |
|+=++O.+.o |
|.o=B+ oo |
+----[SHA256]-----+
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Set up proxy
It is strongly recommended that you set up the proxy by adding the following lines to your .bashrc. You only need to do this once.
export http_proxy=http://proxy:8888
export https_proxy=$http_proxy
Do not forget to source your .bashrc for this to take affect.
Slurm Resource Manager and Job Scheduler in AiMOS
Slurm (used to be Simple Linux Utility for Resource Management) is the cluster management and job scheduler for AiMOS.
Fairshare Allocation Policy
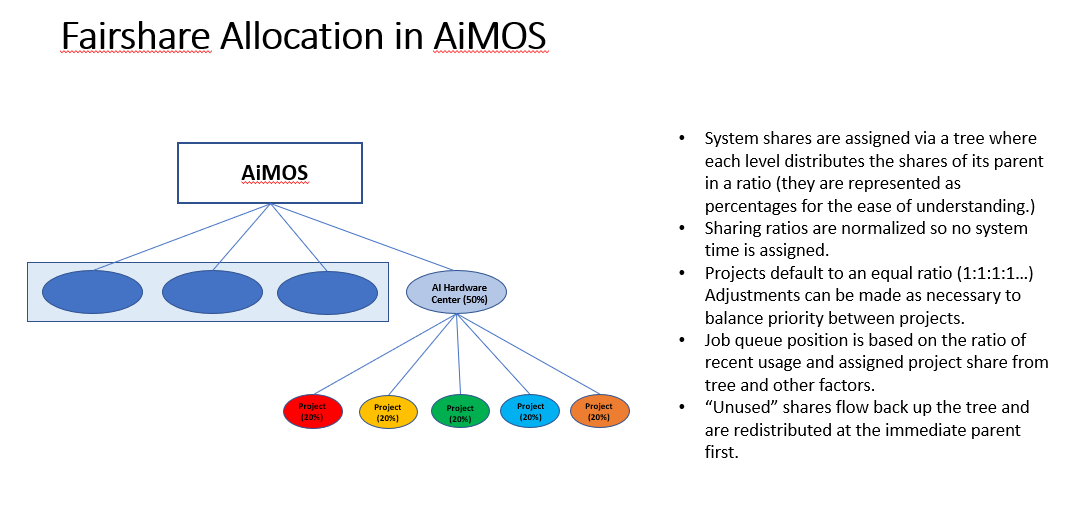
Each partner (e.g., IBM, RPI) is given a fixed slice of AiMOS expressed as a percentage of the whole system.
Within a partner’s “slice”, group projects are defined.
By default, each project receives a fair share of the overall partner level slice.
Inside each project, user accounts are created, and each user receives a fair share of the overall group project level slice.
Fairshare is calculated at the project level. For example, let’s say there are 5 projects in the AI Hardware Center slice of the total systems. This means each project would get 20% of the share. Everyone in the same project would share this 20%, on a ‘first come, first serve’ basis.
Inside each project, user accounts are created, and each user receives a fair share of the overall group project level slice. Fair share is determined as an average over a period of time (month). If the fair share has been consumed within the average time slice, the users in that project will experience longer wait times in the queues, if the system is busy.
For more information on Slurm implementation and frequently used commands see: https://docs.cci.rpi.edu/Slurm/
Job Scheduler Details
The primary input to Slurm is a changing set of jobs that each have a set of constraints: hardware requirements, time limits, layout, etc. Its only output is an ordered queue of jobs.
On the first pass, Slurm is attempting to pack/fit those jobs (with their constraints) into a set of system constraints: what hardware is available, who has access to a node, if jobs can share a node, how long jobs can run on a node, etc.
Another set of constraints is included in the calculation of job priority and ordering: the size of the job, the quality of service (QoS), the job’s age (time in queue), its resource requirements, and group share (fairshare).
These factors are all significant and weighted appropriately because they affect the overall performance of the scheduler and its ability to manage tangible effects like average queue time, job throughput, meet the sharing requirements, and system utilization.
Since all the input are changing regularly - jobs are added, removed, hardware fails, etc - priority is recalculated continuously to reorder the queue as the state of the system changes.
IMPORTANT: Given that time limit, and number of nodes are included in the calculation of the priority of your jobs, you should try to be as accurate as you can with these two requirements of your job. A shorter runtime and fewer number of nodes requested would enable Slurm to fit your job in between the jobs that require longer hours or/and more nodes to run. Hence if you need to debug your code, you should request 1 node and time limit of 1 hour or less. Hopefully that would enable Slurm to allocate a node for you to develop and debug your code.
Job Queue Limits
You need to specify the time required to run your job via option -t <value>. The value is number of minutes. The specified time is also used in the calculation of the priority of your job, hence it is recommended that you specify an accurate estimated time for your job.
The default maximum value is 360 which is 6 hours. It is recommended that you include checkpoint restart in your code to enable your job to restart at the last checkpoint if your job run is longer than 6 hours.
DCS cluster now has a capability for a 48 hour job time limit. This option is not available on the NPL cluster. There are maximum 18 nodes available for the 48 hour time limit. To request this capability, you need to include the following line in your sbatch script:
#SBATCH --qos=dcs-48hr
IMPORTANT: remember that time limit and number of nodes are counted in the project’s allocation. This means that subsequent jobs are impacted in their scheduling, since the project would have used a large number of nodes and time in the queue.
Slurm Frequently Used Commands
For the complete list of SLURM manpages, see https://slurm.schedmd.com/man_index.html
For the summary for SLURM commands and options, see https://slurm.schedmd.com/pdfs/summary.pdf
Frequently Used options for Slurm commands
-n, --ntasks=ntasks number of tasks to run
-N, --nodes=N number of nodes on which to run (N = min[-max])
-c, --cpus-per-task=ncpus number of cpus required per task
--ntasks-per-node=n number of tasks to invoke on each node
-i, --input=in file for batch script's standard input
-o, --output=out file for batch script's standard output
-e, --error=err file for batch script's standard error
-p, --partition=partition partition requested
-t, --time=minutes time limit
-D, --chdir=path change remote current working directory
-D, --workdir=directory set working directory for batch script
--mail-type=type notify on state change: BEGIN, END, FAIL or ALL
--mail-user=user who to send email notification for job state changes
salloc
Allocate resources for a job in real time and start a shell.
[your-id@dcsfen01 ~]$ salloc -N 1 --gres=gpu:6 -t 15
salloc: Granted job allocation 60780
squeue
Report the state of jobs or job steps. By default, it reports the running jobs in priority order and then the pending jobs in priority order.
[your-id@dcsfen01 ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
60780 dcs bash your-id R 1:07 1 dcs249
[your-id@dcsfen01 ~]$ ssh dcs249
Warning: Permanently added 'dcs249,172.31.236.249' (ECDSA) to the list of known hosts.
To display when your pending job will be started:
[your-id@dcsfen01 ~]$ squeue --start
JOBID PARTITION NAME USER ST START_TIME NODES SCHEDNODES NODELIST(REASON)
93765 dcs,rpi pytorch_ your-id PD 2020-03-27T12:34:38 2 dcs[235-236] (Resources)
sbatch
submit a job script for later execution. The script typically contains one or more srun commands to launch parallel tasks.
sbatch ./batch-job.sh
scancel
Cancel a pending or running job or job step.
scancel <JOBID>
sinfo
Report the state of partitions and nodes managed by Slurm.
[your-id@dcs249 ~]$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
debug up 30:00 5 drain* dcs[213,253-254,266],dcsfen02
debug up 30:00 11 down* dcs[040,074,109,119,121,124,126,168-169,173,270]
debug up 30:00 20 drain dcs[026,068,086,154,194,199,206,209-211,216,236,242,246,250,255,257,259-260,269]
debug up 30:00 78 alloc dcs[023-025,027-030,032-036,039,069-073,110-118,120,125,165,170-172,174-193,198,200-205,212,237-241,243-245,247-249,256,261-265]
debug up 30:00 136 idle dcs[001-012,014-022,037-038,041-067,075-085,087-108,122-123,127-153,155-164,166-167,195-196,207-208,214-215,235,251-252,258,267-268]
debug up 30:00 3 down dcs[013,031,197]
dcs up 6:00:00 4 drain* dcs[213,253-254,266]
dcs up 6:00:00 11 down* dcs[040,074,109,119,121,124,126,168-169,173,270]
dcs up 6:00:00 20 drain dcs[026,068,086,154,194,199,206,209-211,216,236,242,246,250,255,257,259-260,269]
dcs up 6:00:00 78 alloc dcs[023-025,027-030,032-036,039,069-073,110-118,120,125,165,170-172,174-193,198,200-205,212,237-241,243-245,247-249,256,261-265]
dcs up 6:00:00 136 idle dcs[001-012,014-022,037-038,041-067,075-085,087-108,122-123,127-153,155-164,166-167,195-196,207-208,214-215,235,251-252,258,267-268]
dcs up 6:00:00 3 down dcs[013,031,197]
rpi up 6:00:00 1 drain* dcs218
rpi up 6:00:00 13 drain dcs[217,219-222,224-229,231-232]
rpi up 6:00:00 2 alloc dcs[223,230]